With a second cat moving in this week, I am even more curious than before about what happens at home when no human is around.
There is a range of products that offer pet monitoring. Given I have an unused Raspberry Pi and a spare webcam lying around, I decided to DIY the solution.
Building a pet cam using a Raspberry Pi, a webcam and tailscale
As it turns out, this is easy: Take a Raspberry Pi, connect a webcam and install motion – an open source tool that exposes the webcam stream over the local network.
To enable remote access, I used tailscale which creates a private network for all my devices, no matter where they are located physically.
One thing to note: Pick the right Raspberry Pi. I started off with the model B+ (from 2014) which is a little underpowered and even has issues running the current Raspberry Pi OS smoothly. Luckily, I also had a “Pi 3 Model B” sitting in a drawer which did the job just fine.
My final setup: A headless Raspberry Pi – no keyboard or display attached. Plug in webcam, ethernet and power, and the stream will start automatically.
Save snapshots when motion detected
The motion project comes with some handy features: Whenever motion is detected, it will save a snapshot frame and even short videos. These are stored on the Pi (under /var/lib/motion by default) and include the time of the event.
Even when not watching the webcam stream, these recordings allow a summary of what the furballs were up to while I’m gone.
Setting the trap
Spoiler: She ended up taking the bait
Tailscale: Pretty cool
I hadn’t used it before, but tailscale really was perfect for this case: The Raspberry Pi is one device in my virtual network. The other two I’ve added are my laptop and my phone.
Anytime I want to check the webcam stream I simply open the browser and access the (virtual?) IP of the Pi.
Accessing the webcam from my laptop
On the iPhone, I added that URL to the home screen so the ominous toilet stream is always in reach.
Accessing the webcam from my iPhone
Next level: Five eyes
The initial setup was easy. I now have one webcam that I can place anywhere (anywhere the ethernet cable reaches, that is). A set of these would be cool so that I could monitor all movement in the flat.
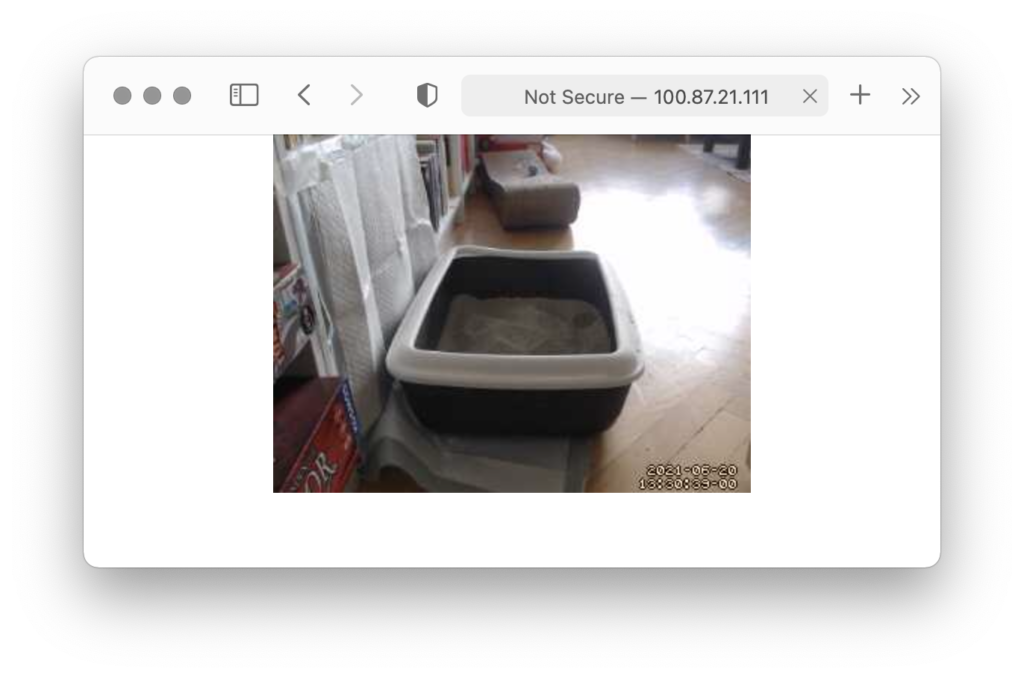
My ambitions to build the next NSA for cats are limited though, so I’ll probably stick to a single cam and point it at one key location. Right now it’s looking at the litter box and I’m working on a spreadsheet to plot the bowel movements of the little one. Uhm, yeah.
The new oil
Another idea for the next step: Collect the visual data over time and run some vision algorithms. How often do they eat? Do they really sleep 16 hours a day? Who spends more time in each room? All of them cool ideas (which I’ll never implement, let’s be honest).
This was a quick project. I can now check in on my cats when I’m out and about. A Saturday afternoon well spent.
Ever since I’ve picked up my first set of bean bags as a kid, juggling has become a hobby that has stayed with me over the years. In my later teens and during my time at university, one of my part-time jobs was being a juggling teacher. I worked at a local youth club, at events and fairs, and had the chance to teach juggling to many people — starting from just 4 or 5 years old to seniors in their late 70s.
Juggling? Works everywhere. This is me, at a tea plantation on the Azores in 2018. How long till AI can do the same?
Fast forward to today. In the last few years, I have been working in the field of AI, working with my team to build computer vision systems that understand human motion and assist people in learning how to move correctly (i.e. with fitness exercises in our latest product).
Doesn’t this sound like something I should combine with my long-time hobby? While every person learns differently and at their own pace, I think juggling is a great skill to learn yourself while being assisted by an AI. When it comes to juggling, I’ve observed most people struggle in a similar manner to overcome common obstacles as they progress — a perfect example to put into an application.
The idea
Here’s the idea: You pick up a set of juggling balls and position yourself in front of your webcam. Step by step, you progress through basic juggling moves as software analyses the live video and provides feedback: Is your juggling pattern stable? Should you throw higher or lower? Are your hands positioned correctly? Is your rhythm fine?
With this in mind, I sat down one weekend this winter to build an AI-powered juggling teacher. In this post, I’ll show you how I did it.
Understanding what’s happening inside a video
To analyze the video of a person learning how to juggle, we’ll train a neural network (also “neural net” or “model”). If you are not familiar with neural networks, don’t be intimidated: It’s a concept that sounds fancy and comes from the field of Artificial Intelligence, but ultimately you can imagine it as a function, or a simple black box: We input a video clip and it returns as the output some information about that video.
Visualisation of my idea at a high level: A video stream is encoded by its pixel values and passed through a neural network. The network digests the visual information to produce a classification decision: What action is happening in the video?
We’ll set up our neural network to be able to classify a given video clip: Given a video, what visual class does the video belong to. A class in our case is the name of an action that is happening in the video – like “throwing 1 ball and dropping it”. In our application, we’ll use that visual class in order to give appropriate feedback to the user.
How to train the neural network
But how does the neural network know what to do? How does it know the difference between correctly tossing a ball versus dropping a ball? Well, it has to learn it first, which means that we need to train it.
Training a neural network means presenting it with example video clips of all the visual classes it should be able to recognize. Initially, the neural net doesn’t know much. It simply guesses what’s inside the video. If a guess is incorrect, we can adjust the internal parameters of the function (= of the neural network) so that the network is improved based on the error it just made. We’ll do this over and over again with all videos we’ve prepared for training until the network doesn’t get any better. At that point, we stop training and move on to build the application around it. But first, we need to prepare some video data for the training process.
Data collection
To train the neural net, we need a training dataset — that is a collection of video clips, each belonging to one distinct visual class we want the net to be able to recognize later. For the juggling use-case, I wanted the network to recognize the following:
How many juggling balls is the person using (1, 2, 3, or zero)?
Common mistakes people make when learning how to juggle: Throwing too high or too low, not standing still, having the hands too close or too high in the air, and a few others.
It is also good to add a few background and contrastive classes — examples of other things that can happen in the video but aren’t exactly part of the juggling activity. I’ve recorded videos of an empty video frame, a person entering or leaving, reaching towards the webcam when controlling the computer, and more.
2 balls: A single repetition
3 balls: A good pattern, continuously
Throwing too high
Throwing 2 balls at the same time
Continuous juggling, but not at a steady rhythm
Entering the webcam view
Pretending to juggle, no objects used
All in all, this class catalog contains 27 different classes. I’ve recorded 545 video clips, each 3 seconds long. This took me around 1 hour. 70 videos went into a hold-out validation set so that I ended up using 475 videos to train the network. Is this enough data? We’ll discuss this in a bit. First, let’s have a look at the actual neural network.
The neural network
Neural networks come in all kinds of flavors. For the juggling project, we want a network that can process a video stream, digest its visual characteristics to produce a classification output, and be compact enough to run in real-time.
I got all of this out-of-the-box by using the SDK we are developing and currently open-sourcing at Twenty Billion Neurons: SenseKit, an open-source project (work in progress) that makes it easy to train a video classifier without needing millions of videos.
The neural network architecture is a MobileNet-style neural network. Models of this architecture are popular for computer vision applications because they are designed for visual data while being compact enough to run in real-time on many devices, even smartphones. 3D convolutions instead of 2D convolutions allow powerful feature extractors on videos that include motion.
These “deep” neural networks (= many layers of feature extractors) require a lot of data to be able to learn useful features. One trick to get away with less data is called transfer learning: We don’t train the network from scratch. Instead, let’s take an already trained version and only slightly re-train it for our specific juggling task. In fact, the SenseKit version of the network comes with a pre-trained model. This means that my handful of juggling videos are enough to teach the network about juggling and the different kind of juggling mistakes we want the application to react to.
Typically, training a video classification network requires thousands, if not millions of videos. With that in mind, it’s quite impressive that I could teach the network a completely new set of activities with just a few hundred videos. In addition, not training from scratch gives us a huge speedup. Training the juggling net took less than 10 minutes on a GPU machine (NVIDIA Geforce 1080 Ti). As a comparison, these big networks can often take days to train from start to finish.
The juggling trainer in action
Having trained the network, I built a small juggling trainer application in Python that takes care of the following:
Neural network input. The application reads the live video stream from the webcam and feeds all frames to the neural network. Internally, multiple frames together are just like one video clip to the network. This is the same behavior that we mimicked during the training process, only then we were reading the frames from the video clips in our training data.
Neural network output. Every time we pass new data to the neural network, it produces an output: The visual class that the network determined from the video input.
Extract juggling information. As we’ve picked our class catalog to encode different information (number of objects, the action performed, quality of action performed), we can extract the different pieces from the recognized class name. For example, any prediction of a class name that starts with 2b_... will be interpreted as “2 balls” being present in the video.
User interface. UI is fancy for saying that the application opens a window to show the webcam stream and overlay it with the juggling information we’ve extracted.
Based on the juggling information I can extract from the recognized class name, the interface displays the following information:
Object count: How many balls is the person juggling?
Trick performed: If the user performs a trick correctly (3 ball shower in the video), they receive positive feedback.
Quality of juggling pattern: If the juggling pattern is stable, give positive feedback; if it’s unstable, give negative feedback.
This is what it looks like in action:
A short video of what the juggling teacher (more precisely: the neural network) looks like in action
Limitations
No data diversity. There is exactly 1 person in the training data, plus the demo video was recorded with the same person (yours truly). From other experiments at work I know that the pre-trained network transfers very well to other people, but to move this juggling case forward, I’d need some data recorded by multiple people in different settings.
Some classes are unreliable. I did play around with more nuanced feedback: Are you throwing too high or too low, are you not throwing at a steady pace, and similar. For these more subtle differences, the predictions aren’t stable enough yet. Looking at the training data, I found that I didn’t record those “mistakes” in a consistent fashion. I think cleaning the training data a little and adding some clearer recordings could help.
A demo, not a juggling trainer yet. Right now, there is no application logic aside from the debug display shown in the video. What I envision is a step-by-step guide to walk the user from 1 ball tosses all the way to a stable 3 ball pattern and maybe their first trick.
Not shareable. I’ve trained the neural network based on an early internal version of the SDK, so the license currently doesn’t allow me to share the network freely on the internet. There’s a research version of the model coming, so I may port my juggling code to that one. In addition, it would be cool to package the juggling demo up in an accessible format, like a mobile app or an in-browser demo. Let’s see.
A glance at the past
The idea to combine juggling and computer vision isn’t new, of course. Not to the world (check YouTube), but also not to me. Back at university (think 2014), two friends and I used the Kinect depth sensor to look at juggling patterns. It took us a few weeks and some failed attempts to produce a demo, held together by some carefully tuned thresholds. It was fun and we were able to produce some entertaining visualizations, but the demo was prone to misclassifications. To actually react to a person’s juggling pattern wasn’t feasible with our solution back then.
An alternative approach from 2014: Using the Kinect depth sensor to localize hands and balls and use the coordinates for some fun visualizations. Limitations: No understanding of good or bad juggling patterns, no recognition of juggling mistakes.
Conclusion: A lot is possible in one afternoon
Throwing together a few videos and fine-tuning a neural network: It’s amazing to see and experience how much is possible with the tooling that’s available in 2021. Yes, I’ve only built a prototype of a demo so far — but the goal of building a real juggling trainer powered by computer vision isn’t out of reach. Looking back at my early attempts with the Kinect six years ago and comparing it to my recent attempt, it’s almost unreal to see that the same can be achieved in just one afternoon of work. I don’t know if I’ll push the project further than this, but it sure was a lot of fun.
If you have an idea for a similar computer vision project, I recommend you follow the progress of SenseKit. It comes with some built-in demos and provides everything you need to train your own video classification network similar to my juggling project.
Earlier this year, afewfriends and I have started a remote Data Science study group. Since then, we’ve met once a week to talk about Data Science, Machine Learning, and Python. Our aim is to get better, together. In this article, I want to share how we’ve set up the group and what has been working for us so far.
Why?
There are a plethora of reasons why running a remote study group for any topic is a good idea. Here’s what motivated me.
Reach personal goals. Improving and practicing my Data Science and Machine Learning skills outside of work has been part of the goals I’ve set for myself at the beginning of 2020.
Healthy peer pressure. Social pressure works, at least for me: I know that I would have a hard time sticking to a weekly cadence of studying on my own, but if a peer group holds me accountable to at least show up, I would always try to have something to show for it.
Share knowledge. If you find a group of motivated people, they will bring different experiences and questions to the round. This leads to healthy discussions and skill sharing.
Study from home. Remote study groups are very compatible with a pandemic lifestyle.
Find a group and make it easy to commit for everyone
To get started and get others on board, I made two choices to reduce the initial friction of getting things running:
Set the initial topic. “I am going to read the following book on Data Science in the next few weeks. It’s available as a free PDF. Do you want to join me?”
Reasonable commitment. We’ll meet once a week for a video call of 1 hour. It won’t ever take longer.
This was easy to say “Yes” to and three friends immediately joined me.
Read a book together and discuss notes afterwards.
Start simple: Read a book together
The first few weeks, we’ve read a book together. The goal was to start broad with a high-level overview. Our first book was Steven Skiena’s The Data Science Design Manual, which is available for free from Springer.
The book lends itself well for this purpose because it goes over central Data Science topics at a conceptual level. In some chapters, Skiena dives into algorithms, but not too deep. As an overview to get our group started, it was a good choice. Moving forward, most of us agreed to pick a book that has more in-depth explanations and code examples to encourage trying things out.
We’ve read 1-2 chapters per week, depending on their length and complexity. In our weekly discussion, we went through our notes and shared in turn, asking: “What’s one thing you’ve learned from this chapter?” These discussions easily filled 60 minutes and I think it never got boring.
Intensified Learning: Code together
It’s hard to argue that trying things out yourself will lead to deeper understanding, so we’ve tried from the start to incorporate that. While reading, we would experiment with one of the mentioned algorithms or look at a dataset linked from one of the chapters. Having finished the book, we continued that practice: Everyone picked a personal data project to work on, and we updated each other once a week. These data projects were all motivated by challenges available on Kaggle, and we had good fun toying around with them.
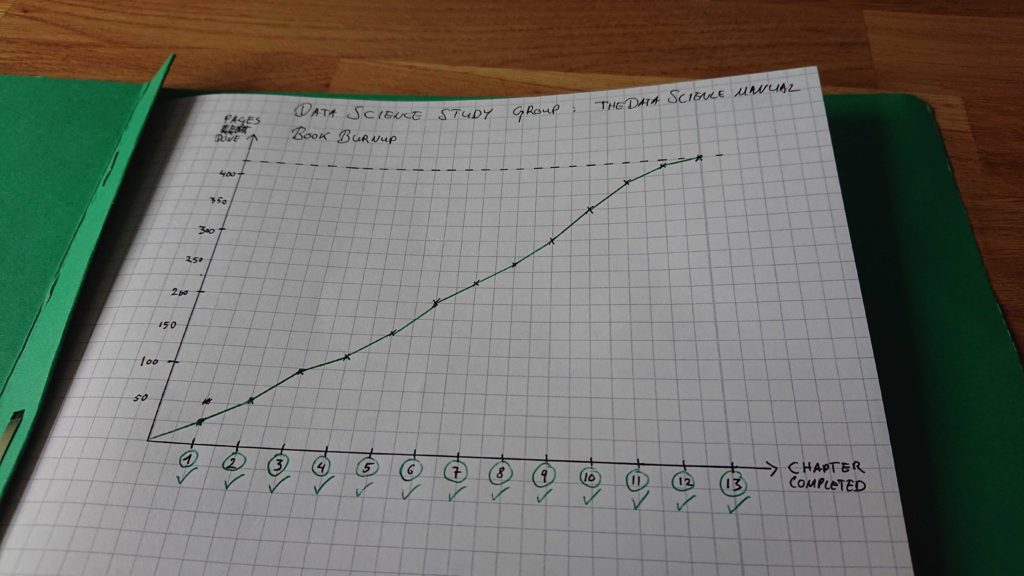
When you simply want to read a book, but are too used to agile practices. Voila, a book burnup.
Learning with Pandas
We’ve recently moved on to a new book: Wes McKinney’s Python for Data Analysis. As the Pandas library is the de-facto standard for data handling in Python, a book by the author of Pandas seemed like the right choice. In the group, we have different levels of experience with Pandas, but revisiting the foundation and strengthening the practical skills were favored by all of us. As this book is heavy on code examples, we hope to get a good balance of reading and coding in as we move along.
Moving forward
Reading a book, working on mini-projects, starting with the second book. It almost feels like we’ve entered “Season 3” of our little Data Science journey now. So far, I’ve learned a lot as an individual, and I think as a group we are motivated to keep going, probably experimenting with the format in the future.
The experience of launching a remote study group has been great so far. If you have a topic you want to explore more thoroughly, take this as an encouragement: In the age of video calls and free online resources on every topic imaginable, collaborative learning has become as easy as never before.
If you are interested in anything that is sold nowadays, there is no way around Amazon. For your data science project that requires product data, you may wonder how to access their product data programmatically. Put simply, you have two different options: Speak to the Amazon product API or scrape the website directly.
Average review, date of publication: The results on Amazon include a lot of interesting meta data.
Why the Amazon API may not be the right tool for you
If you can get access to the Amazon product API – great, use it! However, this isn’t as straight forward and reliable as one may think. You need an active partner account and people actually need to purchase things through your links so that your API key actually keeps working.
Of course, it makes sense. Amazon does not need to feed hungry data scientists through an open API. This interface is designed to drive retail business, so it’s supposed to be used by eCommerce sites and the likes. From what I can tell, this may not have been much of an issue in the past, but when I tried my old API key from when I still had referral links online – it wasn’t working anymore:
{"__type":"com.amazon.paapi5#TooManyRequestsException","Errors":[{"Code":"TooManyRequests","Message":"The request was denied due to request throttling. Please verify the number of requests made per second to the Amazon Product Advertising API."}]}
Fair enough, let’s try the more exciting route and scrape the website instead.
Why scraping from the terminal may not work for you
If you’re coming from any kind of data science background, your tool of choice is probably Python, so you fire up a notebook and grab a current copy from an Amazon product search. But behold, what’s this? Ah, we look like a bot, fair enough.
Unless you want to teach your scraper how to fill in captchas, a headless scraper may not work on many modern websites.
We may be able to get away with setting the user agent string and faking a user session somehow. But why not pause on Python and delve into JavaScript land again?
How to scrape right from your browser
When looking for a simple web scrapter, I found artoo.js: An older but cute little JavaScript project to scrape right from your browser.
And yes, it works! artoo.js works through a simple bookmarklet, and then with your own scripts right inside the browser console. The scraped results are downloaded as CSV or JSON.
When writing a scraper, I can recommend writing some debug CSS to highlight the data you want to select.
I spend some time this weekend to create a scraping script to fetch a number of parameters for all items in an Amazon book search. A result then looks like this:
2020 is the year of doing things remotely. It was therefore my home home office and a healthy internet connection that provided the space to participate in the AI for Good hackathon last weekend, organized by Deep Berlin. The task description was broad, but it pointed the teams to work on something related to climate change, specifically the occurrence of wildfires.
As a team of four, we spend the weekend looking at the relation of human activity and wildfires. We focused on data about touristic activity in Northern Spain, an area that has seen intense wildfire seasons in the past.
Final presentation video
(Excuse the nervous beginning, anyone who has attended a hackathon before will be familiar with the last minute push, in this case submitting a final video to the hackathon organizers on time.)
Please accept YouTube cookies to play this video. By accepting you will be accessing content from YouTube, a service provided by an external third party.
If you accept this notice, your choice will be saved and the page will refresh.
Some notes
A few thoughts on what we did and what I took away from the weekeend.
Pandas and scikit-learn
In my day job, I mostly work with Python, and am familiar with deep learning libraries like PyTorch and Tensorflow/Keras. The hackathon was a welcome opportunity to do some hands-on Data Science work again, and I enjoyed using Pandas and scikit-learn for quick data analysis and plotting. What a nice ecosystem.
Free location data
Open street map is an amazing community project providing labeled location data from all around the globe. Open Street Map location data is provided in the osm format. To read these files in Python, we used the osmium package. Reading the file and filtering the nodes for our usecase was straight forward, but loading from that format can take surprisingly long.
Free geo data
Once you start looking, you discover some interesting datasets out there which are freely available. We used the MOD14A1 dataset, which provides satellite data of very recent recordings (up to a few days from today), with access to multiple levels of abstraction in the data format.
Pretty maps in folium
Our team member Markus spend some time creating pleasing visualisations of maps in folium.
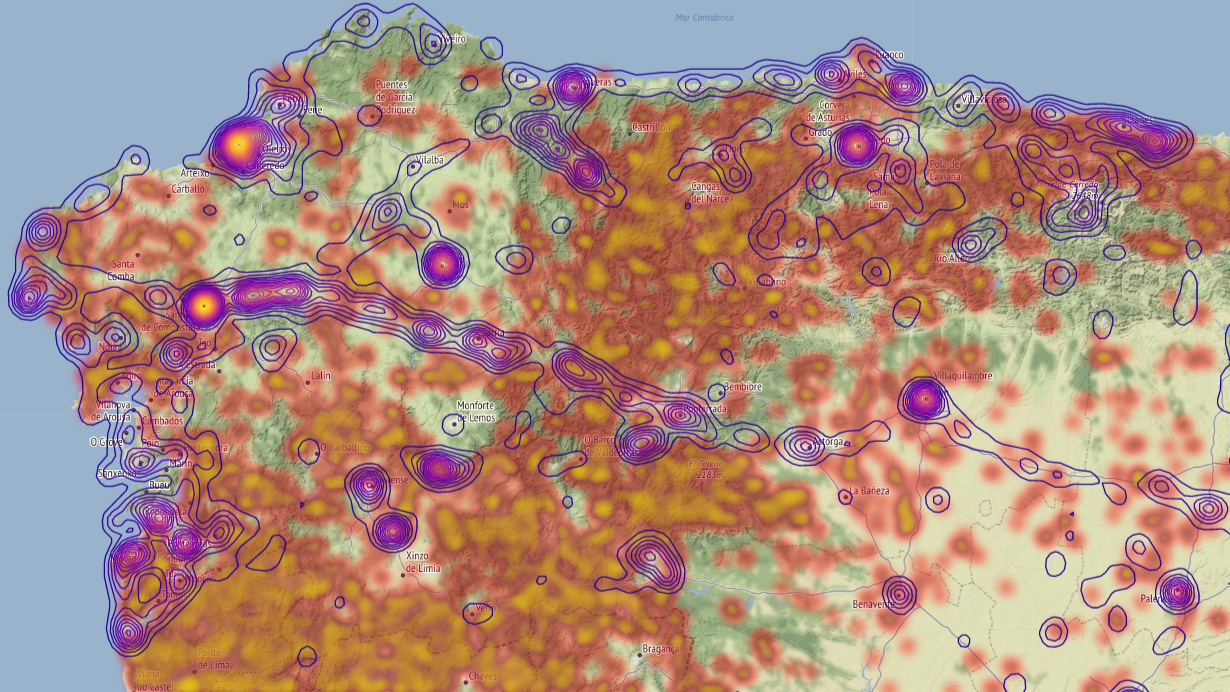
A map of north-western Spain with two data distributions shown. The yellow/red clusters show the locations of wildfires in the past 10 years. The blue outlined areas show locations of high touristic activity. Clearly visible is the Camino de Santiago which extends all the way through Galicia. Map rendered using folium.
What I valued during that weekend was being in my default work environment. Our team quickly developed a working rhythm where we would have a video call for 30 minutes and then disconnect and spend some focused 2-3 hours by our own. I’ve never experienced such a focused working environment at an on-site hackathon.
Obviously, the main shortcoming of being remote was not having the chance to talk to people outside your team, or just bump into someone. Also, there was no way of passively observing what everyone is up to. From what gathered on Slack, many teams actually didn’t constitute properly, and then some lost participants tried to get into other teams, but it wasn’t as easy for them, as it might have been in person.
Would I join a remote hackathon again? Yes, to really get something done on 2 days. To actively socialize, it isn’t the right thing for me, though.