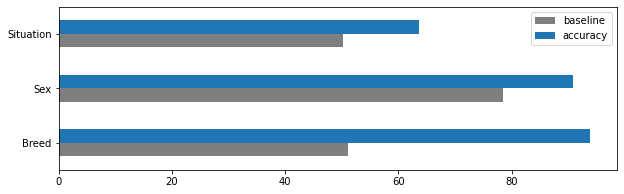I’ve picked the Mastodon instance sigmoid.social, an AI-related instance that is only 3 months old but already has close to 7000 users.
Machines talking to each other
Each Mastodon instance has a public API so it’s straightforward to fetch some basic statistics even without any authentication. I wrote some simple Python scripts to fetch basic info about my home instance.
I wondered: Who are the other users on sigmoid.social? To gain an overview, I fetched the profiles of all user accounts that are discoverable (which at the time of writing means 1300 accounts out of 6700).
Most profiles have a personal description text, typically this is a short bio. I plotted these as an old-fashioned word cloud.
The insight isn’t that surprising: The place is swarming with ML researchers and research scientists, both from universities and commercial research labs.
Who is present on sigmoid.social? Getting an overview from this word cloud generated from user profile bios.
A stroll through the neighborhood
You don’t want to have an account surrounded by AI folk? No problem, there are more than 12,000 instances to choose from (according to a recent number I found). And they can all talk to each other.
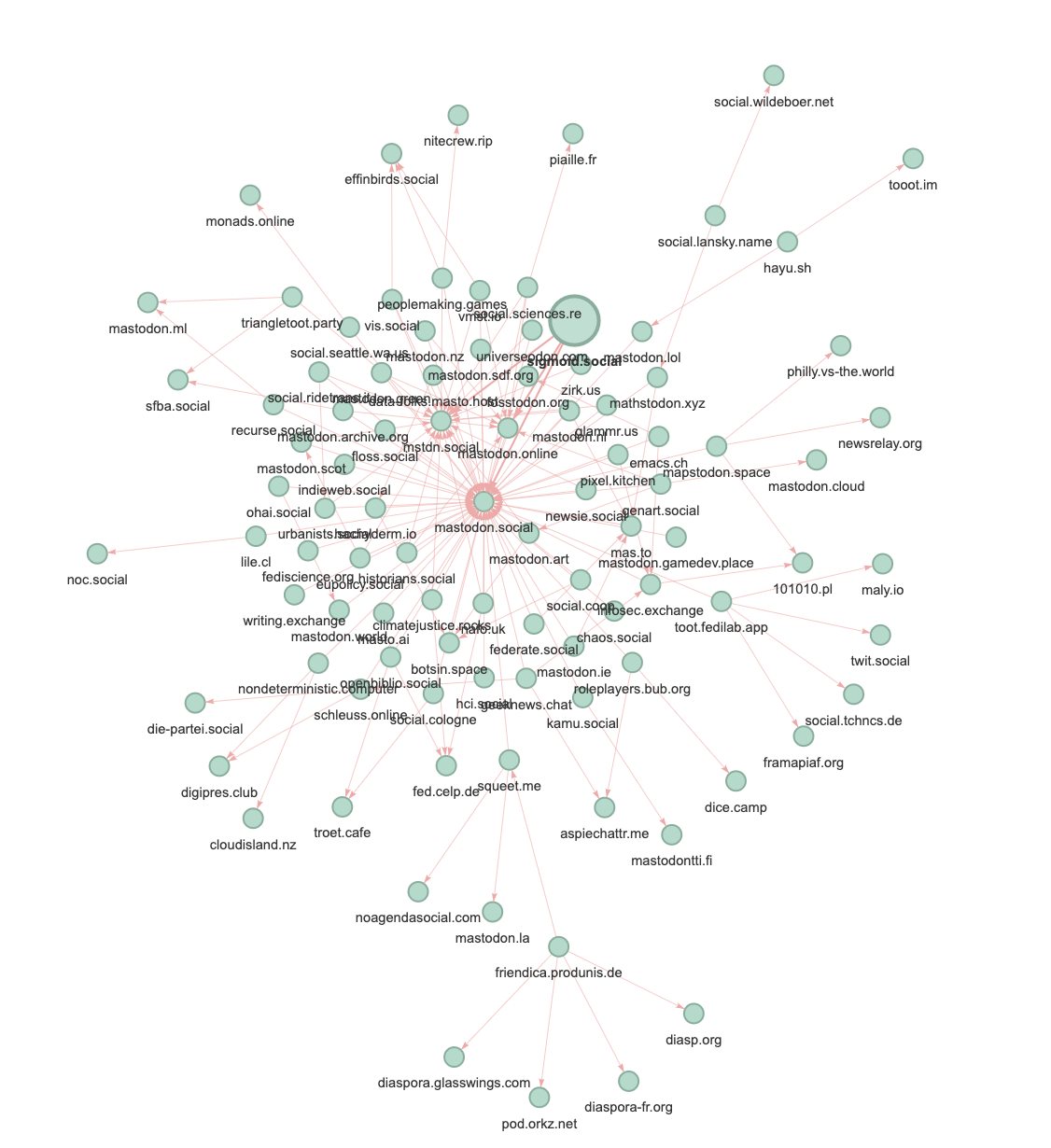
I wanted to see how connected the instance sigmoid.social is and plotted its neighborhood.
This is the method I used to generate the neighborhood graph:
Fetch the 1000 most recent posts present on the instance (which can originate from any other Mastodon instance).
Identify all instances that occur among these posts, and fetch their respective recent posts.
With all these posts of a few hundred instances, create a graph: Each instance becomes a node. Two nodes are connected by an edge if at least five of the recent posts connect the two instances.
My method is naive, but it works sufficiently well to create a simple undirected graph.
The graph yields another unsurprising insight: All roads lead to mastodon.social, the largest and most well-known instance (as far as I know).
Neighboring instances (based on their most recent 1000 toots).
Join us on Mastodon?
I may or may not become more active as a poster myself. In any case, feel free to come over and say Hi: https://sigmoid.social/@florian
For a few years now, the team from fast.ai has been providing free education about deep learning on their website. Their video course promises a hands-on approach that aims to de-mystify the technologies of modern deep learning. With the book “Deep Learning for coders with fast.ai“, they bring these education principles to the written format, either as a printed book from O’Reilly or on Github (for free).
Deep Learning for Coders with fastai & PyTorch: An excellent guide to deep learning for everyone who learns best when reading and writing actual source code.
Before I talk about the book, some context: fast.ai is the name of a website with a video course of the same name. The course is taught using a Python library (called fastai, no dot) which is built on top of PyTorch, the popular deep learning framework. Nomenclature can be confusing. I’ll try to be specific and reference “the fast.ai team” or “the fastai library” in this review of the book.
Teaching structure: Top-down, then bottom-up
The authors are very vocal about their teaching principles: The goal is to “teach the whole game” while skipping the often demotivating mathematical principles at the beginning.
Instead, the first example gives you all instructions needed to train a state-of-the-art image classification model from scratch.
Then, the book progresses deeper into the technical and mathematical foundations, which they use to build up a (simple) version of their fastai library from scratch.
I’m torn: While this structure lowers the barrier of entry, it also makes for a repetitive experience: You encounter the same example many times, just at different levels of abstraction.
What’s in the book
The book covers a wide range of deep learning topics at different levels of depth.
You see practical examples across the main applications areas of deep learning: Computer vision, natural language processing, tabular modeling, and collaborative filtering
All examples are presented with full code listings and everything in the book invites you to go and try things out yourself.
The book presents a wide collection of deep learning techniques that help to get trainings running properly in practice.
From core concepts like gradient descent to advanced architecture constructs: The book comes with many helpful and well-designed illustrations to digest the information.
Popular deep learning architectures are explained, including ResNet, LSTMs, and U-Nets. With a mix of code, visualization, and (some) maths, the authors do a good job of conveying the core ideas of important architectures.
The authors don’t stop at the technical explanations but stress that it’s important to think further. Deep learning is a powerful tool and one that should be used responsibly. Yes, the technical implementor has in fact a responsibility to consider fairness criteria and ask the question “should we even do this at all?”
What I liked
The book is packed with code examples. I personally learn best when implementing something by hand and seeing how an abstract idea translates to actual source code, so this really matched my learning style.
Code examples everywhere. Great for everyone who learns best in this format, myself included.
The language of the text is also very easy to digest. You can tell that the fast.ai team wants to teach a little differently and is genuinely excited about the topic. The text is mixed with personal anecdotes and examples of Twitter conversations to create a sense of community around the otherwise technical topic.
The collection of the latest deep learning techniques and condensed experience is immensely valuable: You learn how a proper training process looks like, which techniques you can use to improve the training and how to investigate if the training is not behaving nicely.
What I didn’t like
My biggest gripe with the fast.ai material is their Python coding style: Everything has to be an abbreviation, apparently. I don’t know why you call a parameter ni when it could just as well be called num_inputs. If the goal is to “reduce jargon”, using explicit naming in the code would be part of that, if you ask me.
Secondly, the teaching principle of “top-down, then bottom-up” has its quirks: You repeat the same example over and over again, just on different levels of abstraction. When I want to look up “the chapter on convolutional neural networks”, it’s not one chapter I have to browse, but 4 or 5. This may make for a good didactic progression but feels quite repetitive at times.
Who should read the book
The name and subtitle of the book capture it quite well: The code-centric approach of learning (and trying out) deep learning lends itself for people who self-identify as “coders” and not so much as academic scholars who want to have the theory laid out first.
Still, it shows that this book originated in a course. The material will stick if you really follow along and try things for yourself. If you don’t, and you’re completely new to deep learning, it will be hard to map out where in the level of abstractions each chapter is situated.
I actually found the book very helpful for myself, because it helped me understand how to use the latest deep learning technologies such as learning rate finder, 1-cycle training, label smoothing, and mixup augmentation. Having worked with deep learning for a while, I still learned quite some new methods and was able to gain a deeper understanding of concepts I had known before.
Summary
Overall, I really liked the book. The authors did a great job of covering a wide range of deep learning applications while showing both: easy-to-use black box examples and the deepest insides of that black box. This helps to de-mystify the ai hype and teaches helpful hands-on skills.
They share a lot of expert advice on how to set up training procedures properly and I actually agree with their claim: Those who really complete this material have a great starting point working in the field of deep learning.
The didactic style may not be for everyone and I personally hope the fastai coding style doesn’t stick, but I am grateful for the fast.ai team’s contribution: Making deep learning accessible for anyone who is interested.
While you can read the book for free on Github, I personally really enjoyed the printed copy: The print is high-quality and it forces you to type out examples yourself rather than copy-pasting everything.
“Meow” — I’m sorry? “Meow!” — Oh, right! Here you go.
What if I could understand exactly what my cat is trying to tell me? We live in 2021, which is basically the future. How hard can it be?
What’s on your mind, little Loki? With the power of neural networks, maybe soon I’ll know.
A dataset of meows
A group of dedicated researchers from northern Italy has recently released a public dataset of cat vocalizations (let’s call them “meows”). 21 cats from two different breeds were exposed to three different situations while a microphone was listening:
Brushing: The owner brushed the cat in a familiar environment.
Isolation: The cat was placed in an unfamiliar environment for a few minutes.
Food: The cat was waiting for food.
In total, the dataset comprises 440 audio files.
Dataset statistics
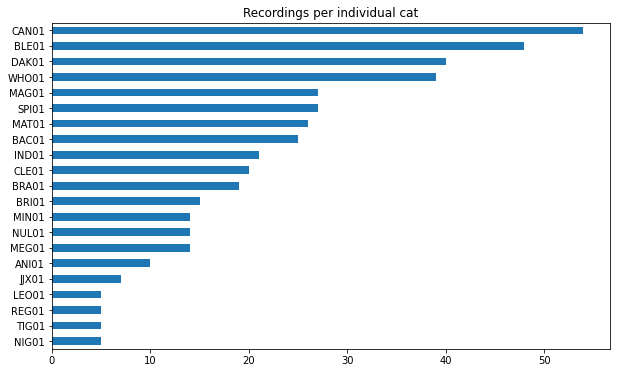
The dataset is not evenly split between those three situations.
Number of recordings per situation
Neither is it evenly split between cat breeds or the sex of the cat.
Number of recordings per breedNumber of recordings per sex of the cat
In fact, some cats occur way more often in the recordings than others. I don’t know why. Maybe “CAN01” is just very talkative whereas “NIG01” prefers to keep to himself?
Number of recordings per individual cat. “CAN01” appears most often and NIG01 least often in the data.
Looking at these distributions is important. When we train a neural network to classify a given voice recording, we want to make sure it performs better than simply guessing the most frequent label.
For example, always guessing “female” when asked for the cat’s gender would be correct in 78% of cases because there are 345 female voice recordings and only 95 recordings of male cats.
Any classifier that is supposed to be useful has to surpass this baseline of “informed” guessing.
Feature
Most frequent label
Absolute count
Relative count = baseline accuracy
Situation (3 classes)
isolation
221 of 440 recordings
50.2 %
Sex (2 classes)
female
345 of 440 recordings
78.4 %
Breed (2 classes)
european_shorthair
225 of 440 recordings
51.1 %
Table that lists the most frequent label per feature. The numbers highlight which baseline accuracy a model has to achieve to be better than guessing.
Now we have an idea of what our data distributions look like. In total, there are three interesting tasks we can have a model learn from the data: (1) What situation was the cat in, (2) what is the sex of the cat, and (3) what is the breed of the cat. It will be interesting to see if these tasks can be learned from the data at all. Let’s start preparing our data to train a model.
Turning audio into images
There are many ways to encode an audio signal before passing it into a neural network. For my project, I am choosing a visual approach: We plot the spectrogram of the audio recordings as an image.
This allows us to use well-established neural networks from the field of computer vision. Also, spectrograms look nice.
Spectrograms are a plot where the location in the image represents a given frequency at a given point in time in the audio file. The brightness of a pixel represents the intensity of the audio signal.
The following example shows one of the recordings as a spectrogram. The time axis goes from top left (zero) to bottom left. The x-axis denotes the frequencies.
We turn our audio recordings into images by drawing their spectrogram
Image classification using a pretrained ResNet
Having turned our audio classification task into an image classification task, we can start with our model training. We are going to train three models for three different tasks:
Given a spectrogram image, classify the situation the cat was in.
Given a spectrogram image, classify the sex of the cat.
Given a spectrogram image, classify the breed of the cat.
I have been playing around with the fast.ai library in the past few weeks which provides convenient wrappers around the PyTorch framework, so I decided to use fast.ai for this project.
Like most deep learning frameworks, it is easy to re-use popular computer vision architectures in fast.ai. With one(-ish) line of Python, you have a capable neural network for image classification at your hands. It comes pre-trained so that you need fewer images for your task at hand.
ResNets are a popular neural network architecture from 2015 that introduced residual connections – a mechanism that improves training behavior and allows the training of (very) deep networks.
The catmeows dataset is quite small, so I was satisfied with the smallest ResNet flavor (called ResNet-18). It has “only” 18 layers and it is still oversized for my 440 images.
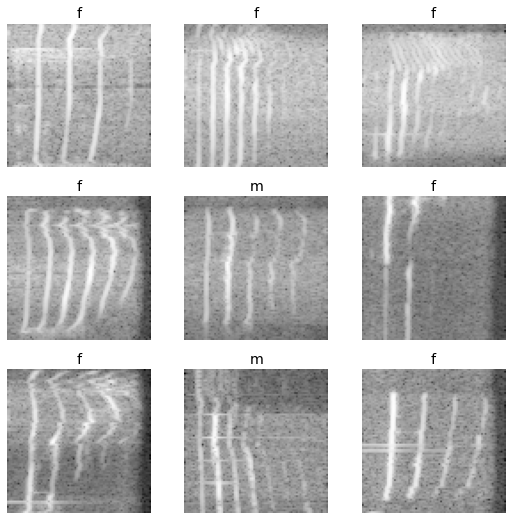
The ResNet implementation wants to have square images as its input, so I took random square crops from the spectrograms during training. The crops were 81 x 81 pixels in size and could be from different points in time of the recording, but always contain the full spectrogram.
The pre-processed images as they go into the neural network. Here we are comparing recordings of female cats with male cats. Do you see a clear difference? I admit that I don’t.
Splitting the data for training and validation
When training a classifier it is important not to show all of your data to the model during training. You want to hold out some samples for validating the classifier during the training process. That way you get an idea if the model learns the training data by heart or if it actually learns something useful.
Sometimes it is fine to take a random percentage of the dataset as the validation set. In this case, I wanted to separate the cats across train and validation split so that the model can’t cheat by memorizing the characteristics of an individual cat.
I took 4 individual cats out of the training data. Their recordings combined made up 66 samples of the dataset, which means 15% of the data was reserved for validation and only the remaining 85% were used for training.
The results
For the three different tasks, the 3 models I trained achieved the following accuracy scores.
Task
Classification accuracy
Guessing baseline (see above)
Situation
63.6 %
50.2 %
Sex
90.9 %
78.4 %
Breed
93.9 %
51.1 %
Results: The accuracy scores of the three task-specific models. For easy comparison, I also list the guessing baseline as described above.
Results plot: Achieved model accuracy (blue) versus guessing baseline (grey).
Across all three tasks, the models performed well above the guessing baseline we have determined earlier.
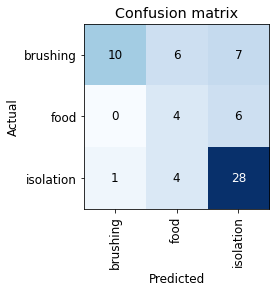
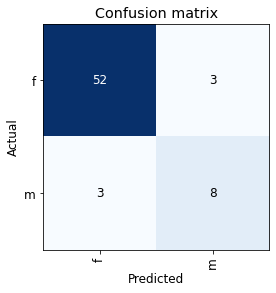
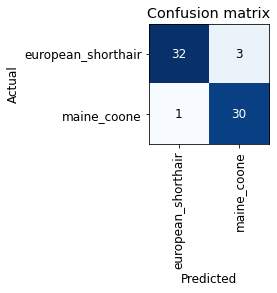
Let’s also take a look at the confusion matrix for each task. A confusion matrix plots each sample of the validation set and indicates how many were classified correctly and which errors were made.
Confusion matrix that shows how well the classification of the situation worked. Some uncertainty shows: 10 samples are incorrectly classified as “waiting for food”, for example.
Confusion matrix of the task to classify the sex of the cat in the recording. 60 out of 66 were classified correctly. Not bad, I think.
Confusion matrix that shows how well the breed was classified. 62 out of 66 samples were classified correctly. I would not have expected this to work at all, to be honest.
What to make of this
First of all, these are quick results. We haven’t built a super AI that understands every single cat in the world. (Yet.)
What these results mostly show are interesting aspects of the dataset: Most of all, I was surprised how well the sex and breed can be told apart by the model. As I made sure to separate individual cats across train and validation data, I do have some confidence that the model didn’t cheat. There may still be some information leakage that I’m not aware of, of course.
“Food”, “brush” and “isolation”. I’m afraid we’ll need a little more vocabulary so that Ginny can adequately explain to me the difficult situation of the Hamburg real estate market. “One room? Fine by me. But I think they tricked me on the square footage on this one”
What to improve
This is a small dataset. ResNet-18 is a big network. This mix can cause problems.
In my case, I am using a pre-trained version of ResNet, so the convolutional features don’t have to be learned from scratch. Still, I found myself re-running the training multiple times with varying success. I think with such little data it is still easy for the model to run into a local optimum and overfit on the training data.
Ideas for improvement:
Try freezing different layers and sets of layers of the network. It’s a tiny amount of data, we wouldn’t want to destroy the pre-trained features by accident. At the same time, spectrograms are not natural images, so fine-tuning probably makes sense.
Some additional data augmentation would surely help to enrich the training data. As these are not natural images but visualizations of an audio signal, I think some augmentation operations make sense (cropping at different points in time, jitter contrast, and brightness to simulate volume fluctuations). Some others are more questionable (perspective transformations, cropping different frequency bands). I haven’t tried them so far, but they could very well improve the results.
To learn more about the data, it would be interesting to extract quantitative audio characteristics and train a logistic regression or random forest on the data. These models are easier to interpret and could help to understand if the models look at something meaningful in the data or if there is some data leakage that allows the models to cheat.
Conclusion
Playing with public datasets is fun! You should try it.
I may continue with this pet project (pet! get it?) or start something fresh with the next dataset that looks interesting.
If you’ve found an issue in my data or training setup, please let me know.
You can find the complete project code in a messy Jupyter notebook on Github.
Machine Learning Design Patterns: A good overview and reference book for machine learning topics in production environments.
If you are anything like me, “machine learning” to you means working with algorithms that adapt their function from data. And while this is true, it’s not the complete story when actually working in the field of machine learning.
Yes, picking the right algorithm and creating the appropriate model is important. But data cleaning, optimizing for production, and setting up scalable infrastructure is just as much part of the day-to-day work on the job.
Along comes Machine Learning Design Patterns, a book that looks at common challenges in practical machine learning. It leaves out model architectures on purpose and instead promises to collect best practices to move machine learning to production.
Each chapter: A (machine learning) design pattern
The book’s title plays on the famous 1994 book by the Gang of Four that popularised the concept of design patterns in software engineering. It comes as no surprise that in Machine Learning Design Patterns, the authors attempt something very similar and identify reoccurring problems from their field.
Each chapter is structured the same way:
What is a common problem in machine learning?
What is the recommended solution?
What are trade-offs and alternatives?
What’s in the book
Written by three engineers from the Google Cloud AI team, the book covers a breadth of topics:
Data Representation
Problem Representation
Model Training
Resilient Serving
Reproducibility
Responsible AI
The early chapters cover topics frequently occurring in the “data science” section of machine learning: What is an embedding, how to work with imbalanced datasets, how to create proper checkpoints during training.
In the later parts, the authors focus more and more on inference and challenges of automation, repeatability and scalability. I now have an idea what a feature store is and how to bridge data schemas when mixing old and new data sources.
A glance at the table of contents. Each chapter follows (more or less) the same structure.
Examples: Python and SQL code
The book is full of examples and they use different technologies: Tensorflow examples in Python, a BigQuery listing, a Google cloud SDK API call.
From the preference of technologies, you notice that the book has been written by Googlers. This doesn’t matter in my mind, because the concepts are always explained clearly, so that porting to other platforms or products should be straight forward.
What I liked
The book covers a wide range of topics and helped extend my knowledge of machine learning to areas I am not an expert in: Resilient Serving, Reproducibility and MLOps in general.
The structure of design patterns lends itself to keep this book on the shelf for future reference. Chapters have a clear motivation and are written to the point, so that I can see myself looking up a design pattern in the future.
Aside from technical topics, the authors also include three chapters about responsible AI and a (brilliant) section about the ML Life Cycle and the AI Readiness of organisations.
What I didn’t like
I have a few complaints, though.
In places it becomes clear that the idea of extracting design patterns from machine learning approaches works well for some topics, but becomes a bit of a stretch for others. I personally didn’t mind this too much, but it’s not as elegant the title of the book suggests.
What I did mind was the fact that this first edition is quite riddled with errors: From figures containing incorrect numbers that don’t align with the text (just annoying) to an explanation of convolution layers that confused convolution with pooling, I think (potentially misleading).
And a final nitpick: The printed copy I ordered was a a monochrome version with low contrast. Many figures were completely indecipherable. A bit disappointing for an O’Reilly book upwards of 40€.
Thin paper, suboptimal graphics. The printed version doesn’t feel very premium.
Conclusion: Great overview to bring ML to production
In conclusion, Machine Learning Design Patterns gives a great overview over common problems you encounter when designing, building and deploying machine learning algorithms.
It will offer valuable content for many in the industry: Data scientists who have never deployed a cloud pipeline, ops experts who are curious about “MLOps” and the product person who wants to understand the constraints and possibilities of modern machine learning development.
My favourite chapter was actually a non-technical one: How to move a team and a whole company from running first ML experiments to becoming an ML-first organisation. This idea ties a lot of the technical and human topics together and it is a topic that excites me personally.
I’ve enjoyed working through this book (together with my data science study group) and it will find a valued place in my bookshelf – to be referenced whenever I encounter one of the problems in the wild again and need a foundational perspective.
Machine Learning Design Patterns, the printed copy. For long-ish reads like this, I personally prefer the physical copy.
Earlier this year, afewfriends and I have started a remote Data Science study group. Since then, we’ve met once a week to talk about Data Science, Machine Learning, and Python. Our aim is to get better, together. In this article, I want to share how we’ve set up the group and what has been working for us so far.
Why?
There are a plethora of reasons why running a remote study group for any topic is a good idea. Here’s what motivated me.
Reach personal goals. Improving and practicing my Data Science and Machine Learning skills outside of work has been part of the goals I’ve set for myself at the beginning of 2020.
Healthy peer pressure. Social pressure works, at least for me: I know that I would have a hard time sticking to a weekly cadence of studying on my own, but if a peer group holds me accountable to at least show up, I would always try to have something to show for it.
Share knowledge. If you find a group of motivated people, they will bring different experiences and questions to the round. This leads to healthy discussions and skill sharing.
Study from home. Remote study groups are very compatible with a pandemic lifestyle.
Find a group and make it easy to commit for everyone
To get started and get others on board, I made two choices to reduce the initial friction of getting things running:
Set the initial topic. “I am going to read the following book on Data Science in the next few weeks. It’s available as a free PDF. Do you want to join me?”
Reasonable commitment. We’ll meet once a week for a video call of 1 hour. It won’t ever take longer.
This was easy to say “Yes” to and three friends immediately joined me.
Read a book together and discuss notes afterwards.
Start simple: Read a book together
The first few weeks, we’ve read a book together. The goal was to start broad with a high-level overview. Our first book was Steven Skiena’s The Data Science Design Manual, which is available for free from Springer.
The book lends itself well for this purpose because it goes over central Data Science topics at a conceptual level. In some chapters, Skiena dives into algorithms, but not too deep. As an overview to get our group started, it was a good choice. Moving forward, most of us agreed to pick a book that has more in-depth explanations and code examples to encourage trying things out.
We’ve read 1-2 chapters per week, depending on their length and complexity. In our weekly discussion, we went through our notes and shared in turn, asking: “What’s one thing you’ve learned from this chapter?” These discussions easily filled 60 minutes and I think it never got boring.
Intensified Learning: Code together
It’s hard to argue that trying things out yourself will lead to deeper understanding, so we’ve tried from the start to incorporate that. While reading, we would experiment with one of the mentioned algorithms or look at a dataset linked from one of the chapters. Having finished the book, we continued that practice: Everyone picked a personal data project to work on, and we updated each other once a week. These data projects were all motivated by challenges available on Kaggle, and we had good fun toying around with them.
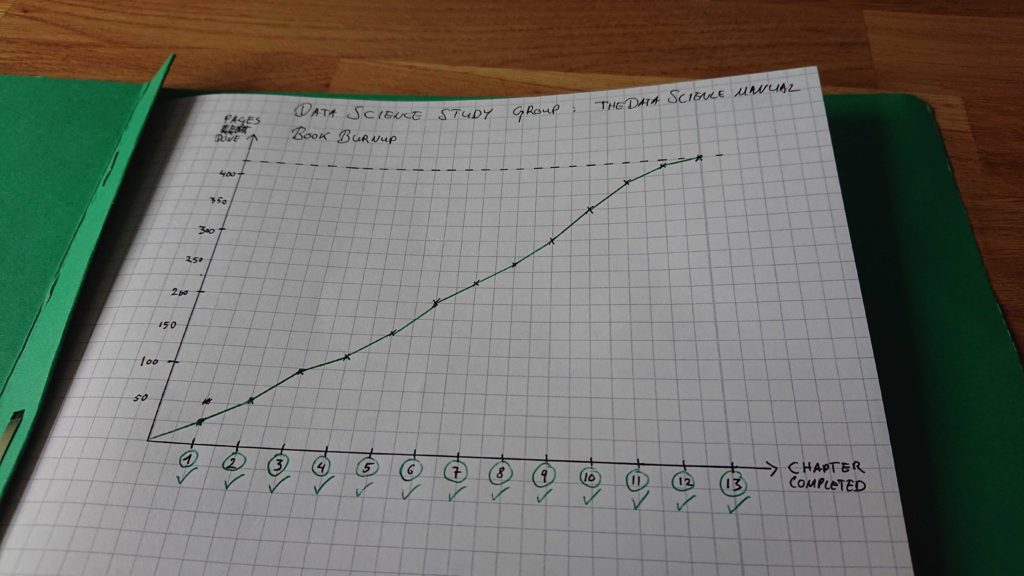
When you simply want to read a book, but are too used to agile practices. Voila, a book burnup.
Learning with Pandas
We’ve recently moved on to a new book: Wes McKinney’s Python for Data Analysis. As the Pandas library is the de-facto standard for data handling in Python, a book by the author of Pandas seemed like the right choice. In the group, we have different levels of experience with Pandas, but revisiting the foundation and strengthening the practical skills were favored by all of us. As this book is heavy on code examples, we hope to get a good balance of reading and coding in as we move along.
Moving forward
Reading a book, working on mini-projects, starting with the second book. It almost feels like we’ve entered “Season 3” of our little Data Science journey now. So far, I’ve learned a lot as an individual, and I think as a group we are motivated to keep going, probably experimenting with the format in the future.
The experience of launching a remote study group has been great so far. If you have a topic you want to explore more thoroughly, take this as an encouragement: In the age of video calls and free online resources on every topic imaginable, collaborative learning has become as easy as never before.
2020 is the year of doing things remotely. It was therefore my home home office and a healthy internet connection that provided the space to participate in the AI for Good hackathon last weekend, organized by Deep Berlin. The task description was broad, but it pointed the teams to work on something related to climate change, specifically the occurrence of wildfires.
As a team of four, we spend the weekend looking at the relation of human activity and wildfires. We focused on data about touristic activity in Northern Spain, an area that has seen intense wildfire seasons in the past.
Final presentation video
(Excuse the nervous beginning, anyone who has attended a hackathon before will be familiar with the last minute push, in this case submitting a final video to the hackathon organizers on time.)
Please accept YouTube cookies to play this video. By accepting you will be accessing content from YouTube, a service provided by an external third party.
If you accept this notice, your choice will be saved and the page will refresh.
Some notes
A few thoughts on what we did and what I took away from the weekeend.
Pandas and scikit-learn
In my day job, I mostly work with Python, and am familiar with deep learning libraries like PyTorch and Tensorflow/Keras. The hackathon was a welcome opportunity to do some hands-on Data Science work again, and I enjoyed using Pandas and scikit-learn for quick data analysis and plotting. What a nice ecosystem.
Free location data
Open street map is an amazing community project providing labeled location data from all around the globe. Open Street Map location data is provided in the osm format. To read these files in Python, we used the osmium package. Reading the file and filtering the nodes for our usecase was straight forward, but loading from that format can take surprisingly long.
Free geo data
Once you start looking, you discover some interesting datasets out there which are freely available. We used the MOD14A1 dataset, which provides satellite data of very recent recordings (up to a few days from today), with access to multiple levels of abstraction in the data format.
Pretty maps in folium
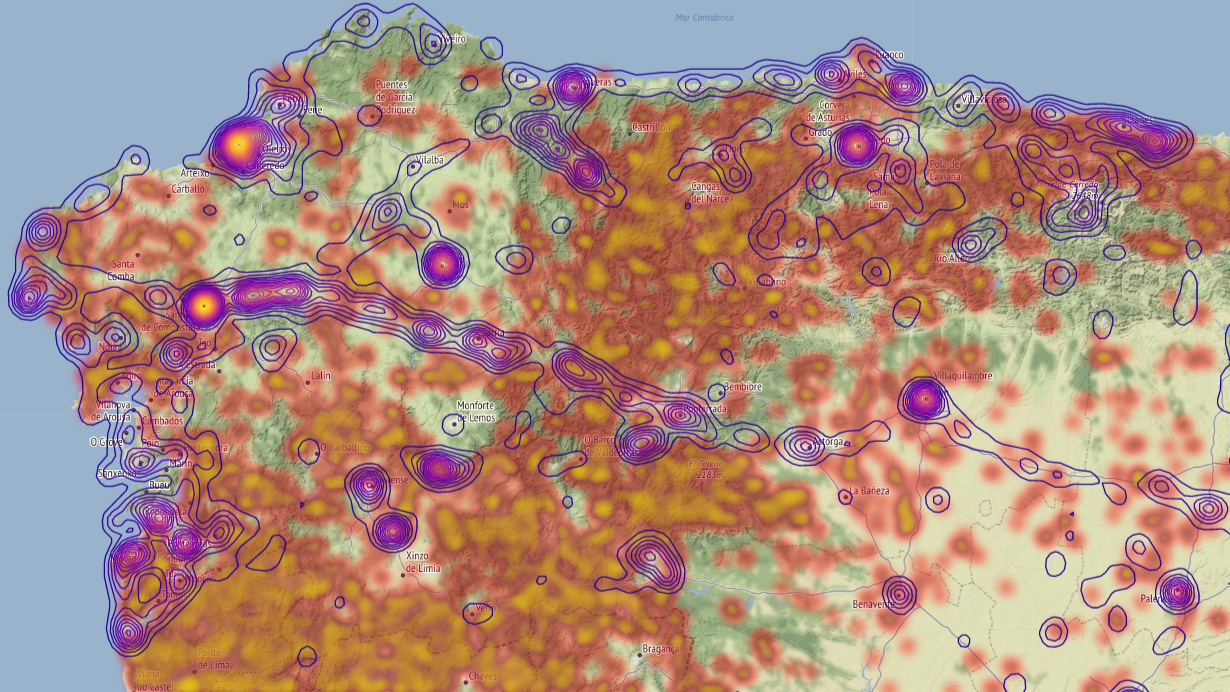
Our team member Markus spend some time creating pleasing visualisations of maps in folium.
A map of north-western Spain with two data distributions shown. The yellow/red clusters show the locations of wildfires in the past 10 years. The blue outlined areas show locations of high touristic activity. Clearly visible is the Camino de Santiago which extends all the way through Galicia. Map rendered using folium.
What I valued during that weekend was being in my default work environment. Our team quickly developed a working rhythm where we would have a video call for 30 minutes and then disconnect and spend some focused 2-3 hours by our own. I’ve never experienced such a focused working environment at an on-site hackathon.
Obviously, the main shortcoming of being remote was not having the chance to talk to people outside your team, or just bump into someone. Also, there was no way of passively observing what everyone is up to. From what gathered on Slack, many teams actually didn’t constitute properly, and then some lost participants tried to get into other teams, but it wasn’t as easy for them, as it might have been in person.
Would I join a remote hackathon again? Yes, to really get something done on 2 days. To actively socialize, it isn’t the right thing for me, though.